En el corazón palpitante de la transformación digital y el Big Data, donde cada clic, sensor y transacción genera información valiosa, reside un componente crítico y a menudo infravalorado: la base de datos (BBDD). No es un mero almacén pasivo; es el sistema nervioso central de aplicaciones web, móviles, sistemas empresariales y plataformas de inteligencia artificial. Elegir el tipo de base de datos adecuado no es una simple decisión técnica; es una estrategia fundamental que determina la escalabilidad, el rendimiento, la flexibilidad y, en última instancia, el éxito o fracaso de tu solución digital.
En Master Code Pro, vamos más allá de listar opciones. Exploraremos los principales tipos de bases de datos, sus fortalezas ocultas, sus debilidades potencialmente críticas y, lo más importante, las consecuencias estratégicas de elegir bien (o mal). Además, desglosaremos por qué la optimización continua no es un lujo, sino una necesidad de supervivencia en el panorama digital actual.
Por Qué la Elección de la Base de Datos ya no es Solo para DBA’s
Imagina construir un rascacielos sobre cimientos de arena. Por muy impresionante que sea el diseño, el colapso es inevitable. Elegir una base de datos inadecuada es el equivalente digital. Las consecuencias son tangibles:
- Cuellos de Botella Catastróficos: Una base de datos que no escala con tus usuarios o tu volumen de datos paraliza tu aplicación.
- Experiencias de Usuario Pésimas: Lentitud, tiempos de espera interminables y errores alejan a los clientes en segundos.
- Costos Descontrolados: Forzar una base de datos a hacer algo para lo que no fue diseñada implica sobreprovisionar hardware de forma masiva.
- Innovación Estancada: Modelos de datos rígidos impiden adaptarse rápidamente a nuevas funcionalidades o tipos de datos (como IoT o análisis en tiempo real).
- Complejidad Insostenible: Implementar «parches» para compensar una elección incorrecta crea sistemas frágiles y difíciles de mantener.
La elección correcta, por el contrario, es un potente acelerador: permite manejar picos de tráfico con elegancia, procesar información compleja a velocidad, adaptarse ágilmente a cambios de negocio y ofrecer experiencias fluidas que fidelizan.
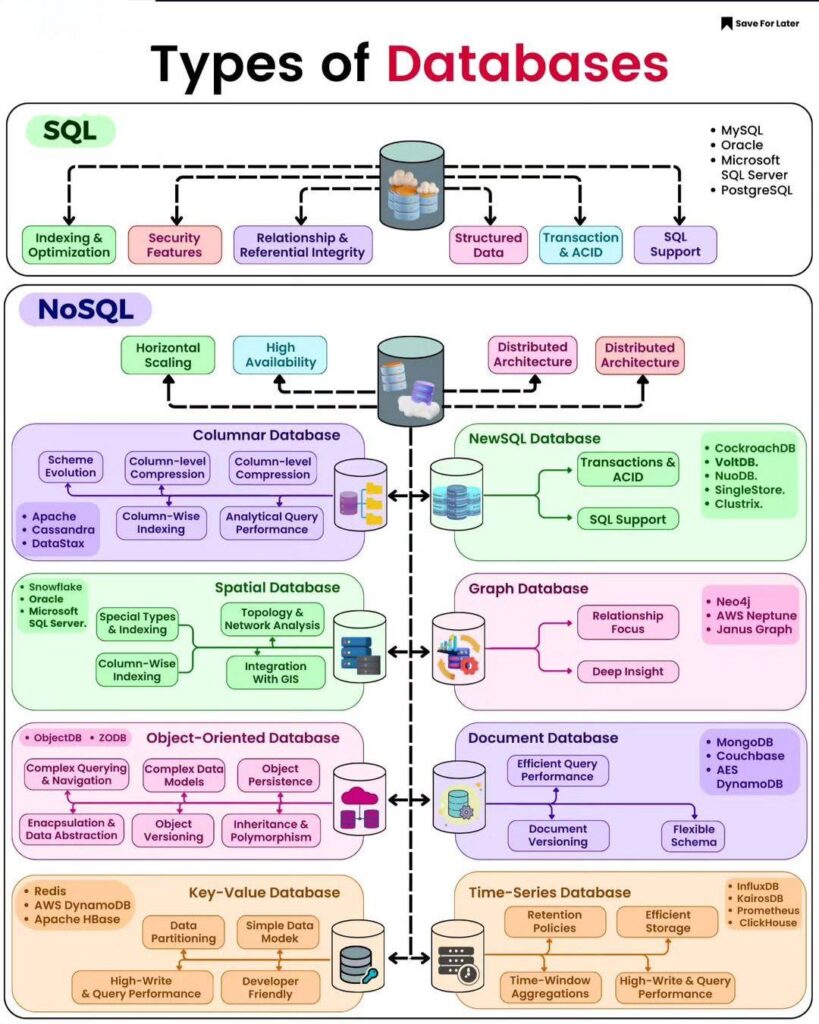
El Mosaico de Opciones: Tipos de Bases de Datos y Su ADN
Lejos de ser un mundo monocromático, el ecosistema de bases de datos es diverso y especializado. Comprender sus esencias es el primer paso hacia una elección acertada.
- Bases de Datos Relacionales (SQL): Los Veteranos Estructurados
- ADN: Organizan datos en tablas (filas y columnas) con relaciones definidas mediante claves primarias y foráneas. Siguen el modelo ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) que garantiza integridad absoluta en las transacciones.
- Fortalezas Clave:
- Integridad Robusta: ACID es oro para transacciones financieras, inventarios, sistemas ERP/CRM donde cada operación debe ser precisa y consistente.
- Flexibilidad en Consultas: Lenguaje SQL estandarizado y poderoso para consultas complejas con joins entre múltiples tablas.
- Madurez y Estándar: Ampliamente adoptadas, con décadas de desarrollo, herramientas maduras de administración y un enorme pool de talento experto.
- Debilidades a Considerar:
- Escalabilidad Vertical (Principalmente): Escalar suele significar «hacer la máquina más grande» (más CPU, RAM, disco), lo que tiene límites físicos y de costos. La escalabilidad horizontal (añadir más servidores) es más compleja que en NoSQL.
- Esquema Rígido: Cambiar la estructura de las tablas (añadir/eliminar/modificar columnas) en sistemas grandes y en producción puede ser costoso y disruptivo.
- Rendimiento con Datos No Estructurados/Variados: Pueden luchar con datos muy jerárquicos (como documentos JSON profundos) o datos sin una estructura fija predefinida.
- Gigantes del Ecosistema: MySQL, PostgreSQL (muy potente y con amplias extensiones), Microsoft SQL Server, Oracle Database.
- ¿Cuándo Elegirlas? Sistemas transaccionales críticos (banca, comercio electrónico – pedidos/inventario), aplicaciones con modelos de datos complejos y relaciones bien definidas, reporting tradicional. [Explora más sobre bases de datos relacionales con ejemplos prácticos en nuestro blog].
- Bases de Datos NoSQL: La Revolución de la Flexibilidad y Escala
- ADN: Un término paraguas para bases de datos que rompen con el modelo relacional rígido. Priorizan la escalabilidad horizontal (añadir servidores baratos) y la flexibilidad del esquema (o esquema-less) sobre las estrictas garantías ACID (aunque muchas ofrecen variantes). Se especializan en tipos de datos específicos.
- Subtipos Principales:
- Documentales (e.g., MongoDB, Couchbase):
- ADN: Almacenan datos en documentos semi-estructurados (normalmente JSON o BSON). Cada documento puede tener una estructura única.
- Fortalezas: Ideal para perfiles de usuario, catálogos de productos, contenido CMS, datos de IoT con variabilidad. Escalabilidad horizontal muy eficiente. Desarrollo ágil (sin migraciones de esquema complejas).
- Debilidades: Joins complejos son menos eficientes que en SQL. Garantías transaccionales multi-documento pueden ser más complejas (aunque han mejorado).
- Clave-Valor (e.g., Redis, DynamoDB):
- ADN: La estructura más simple: una clave única apunta a un valor (que puede ser simple – un string – o complejo – una lista, un hash).
- Fortalezas: Velocidad de lectura/escritura ultra rápida (especialmente en memoria como Redis). Simplicidad extrema. Ideal para cachés, sesiones de usuario, carritos de compra, colas, configuraciones.
- Debilidades: Capacidades de consulta muy limitadas (básicamente, obtener por clave). No aptas para consultas complejas o relaciones.
- Grafos (e.g., Neo4j, Amazon Neptune):
- ADN: Modelan datos como nodos (entidades: personas, productos) y relaciones (conexiones entre ellos: «amigo de», «comprado con»), con propiedades en ambos.
- Fortalezas: Excelencia insuperable para consultar relaciones complejas y profundas (redes sociales, detección de fraudes, recomendaciones personalizadas «quien compró X también compró Y», rutas logísticas). Rendimiento óptimo para preguntas sobre conexiones.
- Debilidades: Menos eficientes para consultas agregadas masivas típicas de reporting (donde SQL brilla). Curva de aprendizaje para el modelado y consultas (Cypher en Neo4j).
- Columnas (e.g., Cassandra, HBase):
- ADN: Almacenan datos por columnas en lugar de por filas. Muy eficiente para leer columnas específicas de muchas filas a la vez.
- Fortalezas: Escalabilidad horizontal masiva y lineal. Alto rendimiento en escritura. Ideal para series temporales (datos de sensores IoT), análisis de grandes volúmenes donde se consultan columnas específicas (no filas completas).
- Debilidades: Menos eficiente para recuperar filas completas o para transacciones ACID complejas. Modelado de datos específico.
- Documentales (e.g., MongoDB, Couchbase):
- ¿Cuándo Elegir NoSQL? Grandes volúmenes de datos no estructurados o semi-estructurados (redes sociales, IoT), aplicaciones que requieren escalabilidad horizontal masiva (global), desarrollo ágil con esquemas flexibles, casos de uso específicos como grafos (relaciones complejas) o clave-valor (caché ultrarrápida).
- Bases de Datos en Memoria (IMDB – In-Memory Databases): La Velocidad del Rayo
- ADN: Almacenan los datos primarios en la memoria RAM principal de los servidores, eliminando la latencia del disco duro (el cuello de botella tradicional).
- Fortalezas Clave:
- Rendimiento Exponencial: Latencias de microsegundos o milisegundos. Transforma aplicaciones que requieren respuesta instantánea.
- Ideal para Tiempo Real: Análisis en tiempo real, trading algorítmico, juegos online multijugador, personalización de experiencias al instante.
- Debilidades a Considerar:
- Costo: La RAM es significativamente más cara que el almacenamiento en disco.
- Persistencia: Requieren mecanismos robustos (snapshots, replicación, logs) para garantizar que los datos no se pierdan ante un fallo (son volátiles por naturaleza).
- Ejemplos: Redis (también clave-valor), MemSQL, SAP HANA, VoltDB.
- ¿Cuándo Elegirlas? Cuando la velocidad de acceso a los datos es el requisito absoluto número uno y el presupuesto lo permite. A menudo se usan como cachés de capa superior o para módulos específicos de ultra-alto rendimiento dentro de una arquitectura.
- Bases de Datos de Objetos: La Extensión Natural de la POO
- ADN: Almacenan datos como objetos, tal como existen en lenguajes de programación orientados a objetos (Java, Python, C#). Eliminan la necesidad del mapeo objeto-relacional (ORM), que puede ser complejo.
- Fortalezas: Alta fidelidad al modelo de objetos de la aplicación. Buen desempeño con objetos complejos y jerárquicos. Simplifica el código de acceso a datos.
- Debilidades: Menor adopción que SQL o NoSQL. Ecosistema de herramientas menos maduro. Menor estandarización.
- Ejemplos: db4o (menos común hoy), ObjectDB.
- ¿Cuándo Elegirlas? Menos frecuente actualmente, pero puede ser útil en aplicaciones muy específicas de CAD/CAM/CAE, simulaciones científicas o donde el «impedance mismatch» de los ORMs con SQL sea un problema crítico.
La Encrucijada Decisiva: Factores Clave para Elegir la Base de Datos Adecuada
No existe la «mejor» base de datos universal. La elección óptima emerge de un análisis riguroso de tus necesidades específicas:
- Estructura de los Datos (Esquema):
- ¿Son datos altamente estructurados con relaciones complejas y fijas? -> SQL.
- ¿Son datos semi-estructurados, no estructurados o con esquema variable? -> NoSQL (Documental, Clave-Valor).
- ¿Son las relaciones entre datos el foco principal? -> NoSQL (Grafos).
- ¿Son datos en forma de objetos complejos? -> Bases de Objetos.
- Volumen y Escalabilidad:
- ¿Necesitas escalar masivamente de forma horizontal (más servidores baratos)? -> NoSQL (Columnar, Documental, Clave-Valor) o NewSQL.
- ¿El volumen es manejable o escalas principalmente verticalmente? -> SQL puede ser suficiente.
- ¿Volúmenes masivos de escritura? -> NoSQL Columnar o Clave-Valor.
- Requisitos de Rendimiento:
- ¿Necesitas latencias ultra-bajas (microsegundos/milisegundos)? -> IMDB (Redis, MemSQL).
- ¿Altas transacciones por segundo (TPS) consistentes? -> SQL o NewSQL.
- ¿Consultas analíticas complejas sobre grandes conjuntos? -> SQL, NoSQL Columnar o Data Warehouses especializados.
- Consistencia y Transacciones (ACID vs. BASE):
- ¿Transacciones complejas con garantías ACID absolutas son críticas (ej. transferencias bancarias)? -> SQL es rey aquí. Algunos NewSQL también.
- ¿Puedes tolerar una consistencia eventual (los datos se propagan y sincronizan con un ligero retraso) para ganar disponibilidad y escalabilidad? -> NoSQL (modelo BASE – Basically Available, Soft state, Eventual consistency).
- Flexibilidad y Agilidad:
- ¿El modelo de datos cambia con frecuencia? -> NoSQL (Documental) ofrece gran flexibilidad de esquema.
- ¿Esquema estable y bien definido? -> SQL funciona muy bien.
- Habilidades del Equipo: ¿Tu equipo domina SQL? ¿Tiene experiencia en MongoDB o Cassandra? La curva de aprendizaje puede ser un factor decisivo.
Más Allá de la Elección Inicial: La Imperativa Optimización de Bases de Datos
Elegir la base de datos correcta es el primer paso crucial, pero no es suficiente. Una base de datos, como un motor de alto rendimiento, requiere afinamiento constante para operar al máximo de su potencial. La optimización no es un gasto; es una inversión con retornos tangibles:
- Beneficios Tangibles de la Optimización:
- Velocidad Suprema: Consultas que tardaban segundos se completan en milisegundos. Transacciones fluyen sin retrasos. La experiencia de usuario se transforma.
- Escalabilidad Eficiente: Manejar más carga sin necesidad de costosas actualizaciones de hardware prematuramente.
- Costos Reducidos: Menor consumo de recursos (CPU, RAM, disco, E/S), reduciendo la factura de infraestructura (especialmente en la nube). Menor tiempo de administración y solución de problemas.
- Alta Disponibilidad Garantizada: Sistemas más estables, con menos caídas e interrupciones relacionadas con cuellos de botella en la BBDD.
- Toma de Decisiones Más Rápida: Análisis y reportes que se generan en fracciones del tiempo anterior.
- Técnicas Esenciales de Optimización (Aplicables en Mayor o Menor Medida a Todos los Tipos):
- Diseño Inteligente: La base de todo. Normalización adecuada (evitando redundancias) o desnormalización estratégica (para consultas específicas). Elección correcta de tipos de datos. Definición clara de relaciones.
- Índices: El Arma Secreta (Usada con Precaución): Crear índices en las columnas usadas frecuentemente en cláusulas
WHERE,JOINyORDER BYacelera las búsquedas exponencialmente. ¡Pero cuidado! Cada índice añade sobrecarga en escrituras (INSERT/UPDATE/DELETE). El arte está en indexar lo necesario sin asfixiar las operaciones de modificación. - Sintonía Fina de Consultas: Analizar consultas lentas (
EXPLAINen SQL, herramientas de profiling en NoSQL). Simplificar consultas complejas, evitarSELECT *, usar joins eficientes, reducir el número de consultas mediante agrupación o mejores diseños de API. - Configuración Óptima del Motor: Ajustar parámetros clave de la base de datos según la carga de trabajo y los recursos disponibles (tamaño del buffer pool, cachés de consultas, conexiones máximas, configuración de escritorio WAL – Write Ahead Log).
- Estrategias de Almacenamiento Avanzadas:
- Particionamiento: Dividir grandes tablas/colecciones en partes más manejables (por rango, hash, lista) para distribuir la carga de E/S y mejorar el rendimiento de consultas.
- Replicación: Crear copias (réplicas) de la base de datos para distribuir la carga de lectura y proporcionar alta disponibilidad (fallover).
- Sharding (Fragmentación): Distribuir los datos de una sola tabla/colección horizontalmente a través de múltiples servidores o clústeres. Esencial para escalabilidad horizontal masiva en NoSQL y algunas SQL modernas.
- Compresión: Reducir el tamaño físico de los datos en disco, ahorrando espacio y mejorando la velocidad de E/S (especialmente útil en Data Warehouses y bases columnar).
- Mantenimiento Proactivo: Tareas periódicas como:
- Actualizar Estadísticas: Ayudan al optimizador de consultas a elegir los mejores planes de ejecución.
- Reconstruir/Reorganizar Índices: Eliminar fragmentación interna para mantener su eficiencia.
- Purgar Datos Obsoletos: Eliminar registros antiguos o innecesarios (archivando si es necesario) para reducir el tamaño y mejorar el rendimiento.
- Copias de Seguridad Rigurosas y Pruebas de Recuperación: No negociables para la continuidad del negocio.
La Base de Datos como Activo Estratégico
En Master Code Pro, entendemos que la base de datos no es un componente aislado, sino el cimiento sobre el que se construyen experiencias digitales competitivas y sistemas empresariales resilientes. Elegir el tipo adecuado – relacional para la integridad transaccional, NoSQL para la escala y flexibilidad del Big Data, grafos para las relaciones profundas, IMDB para la velocidad extrema – es una decisión arquitectónica con profundas implicaciones en el rendimiento, los costos y la capacidad de innovación.
Pero la elección inicial es solo el comienzo. La optimización continua es el proceso que extrae el máximo valor de esa inversión, garantizando que tu sistema no solo funcione, sino que vuele, escale sin esfuerzo y soporte las demandas del futuro.

